블로그
엑셀 표준편차(Standard deviation) 구하는 법: 함수 선택부터 해석까지

두 팀의 월간 매출 평균이 똑같이 500만 원입니다. 어느 팀이 더 잘하고 있을까요? 평균만 보면 모릅니다. 한 팀은 매달 꾸준히 500만 원을 찍고, 다른 팀은 어떤 달은 200만 원, 어떤 달은 800만 원입니다. 표준편차를 보기 전까지 이 차이는 보이지 않습니다.
그런데 막상 STDEV.P와 STDEV.S 중 어떤 걸 써야 할지 헷갈리고, 숫자가 나와도 이게 큰 건지 작은 건지 판단이 안 됩니다. 함수는 쉬운데 해석이 어렵습니다.
이 글에서는 함수 선택 기준부터 결과를 실무에서 올바르게 해석하는 방법까지, 표준편차를 제대로 쓰는 법을 정리합니다.
표준편차란? 실무에서 언제 쓰는가
표준편차는 데이터가 평균을 중심으로 얼마나 흩어져 있는지를 하나의 숫자로 요약하는 통계 지표입니다. 값이 클수록 데이터 간 편차가 크고, 작을수록 값들이 평균 근처에 몰려 있다는 의미입니다.
표준편차는 단독으로 쓰기보다 평균과 함께 볼 때 진가가 나옵니다. 두 팀의 평균 판매량이 같아도 표준편차가 다르면 성과의 안정성은 전혀 다릅니다.
실무에서는 월별 매출 변동성을 파악할 때, 제품 불량률의 일관성을 검토할 때, 설문 응답 점수의 분포를 비교할 때, 팀별 업무 처리 시간의 균일성을 분석할 때 자주 활용됩니다. 평균만 보면 숨겨지는 리스크나 불안정성을 표준편차가 보완해 줍니다.
엑셀 표준편차 함수 차이: STDEV.P vs STDEV.S
엑셀에서 사용하는 STDEV 함수는 크게 두 가지로 나뉩니다. STDEV.P와 STDEV.S의 차이가 바로 그것입니다. 두 함수는 분모 계산 방식이 다르기 때문에, 상황에 맞지 않는 함수를 고르면 결과값이 달라집니다.
핵심 판단 기준은 하나입니다. 내가 가진 데이터가 분석 대상 전체인가, 아니면 일부만 뽑은 것인가입니다.
STDEV.P: 모집단 전체를 갖고 있을 때
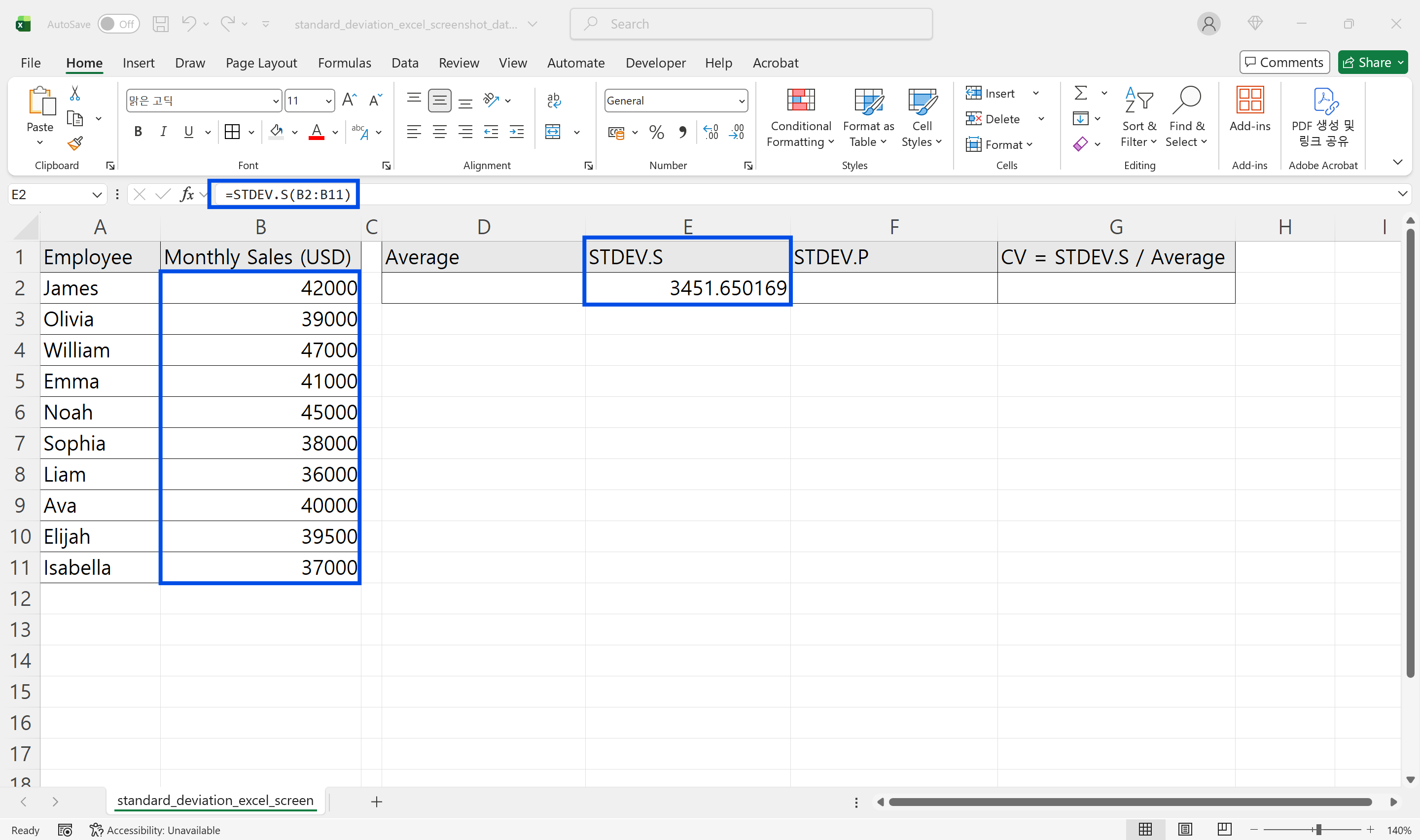
STDEV.P는 입력한 데이터가 분석 대상의 전체 모집단이라고 가정하고 표준편차를 계산합니다. 분모에 전체 데이터 수, 즉 N을 사용합니다.
예를 들어 우리 팀 10명 전원의 월간 실적 데이터를 분석하거나, 특정 공장 A라인의 2024년 전체 불량률 데이터를 갖고 있다면 STDEV.P가 적합합니다. 이 데이터가 내가 관심 갖는 대상 전체라고 말할 수 있을 때 선택합니다.
=STDEV.P(B2:B11)
STDEV.S: 일부 표본 데이터를 분석할 때
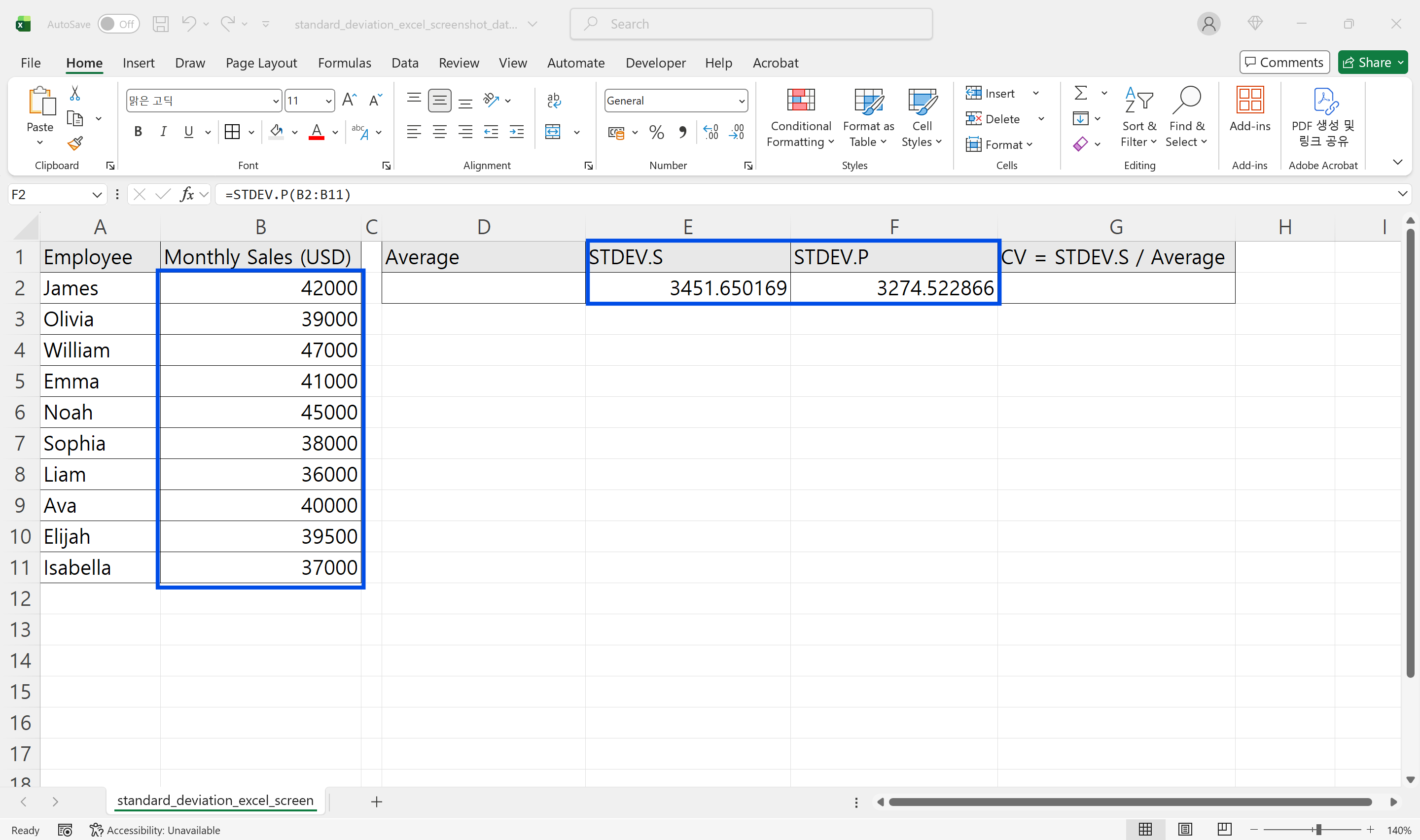
STDEV.S는 데이터가 전체 모집단 중 일부를 샘플링한 것이라고 가정하고 표준편차를 추정합니다. 분모에 N-1을 사용해 표본 오차를 보정합니다.
전국 고객 중 200명을 무작위 추출해 만족도를 분석하거나, 이번 달 주문 건 중 일부만 뽑아 처리 시간을 검토하는 경우가 이에 해당합니다. 실무 데이터는 전체를 다 갖고 있지 않은 경우가 많아 STDEV.S가 기본값처럼 쓰이는 일이 많습니다. 참고로 엑셀에서 =STDEV()를 입력하면 STDEV.S와 동일하게 동작합니다.
=STDEV.S(B2:B11)
엑셀 표준편차 계산 단계별 가이드
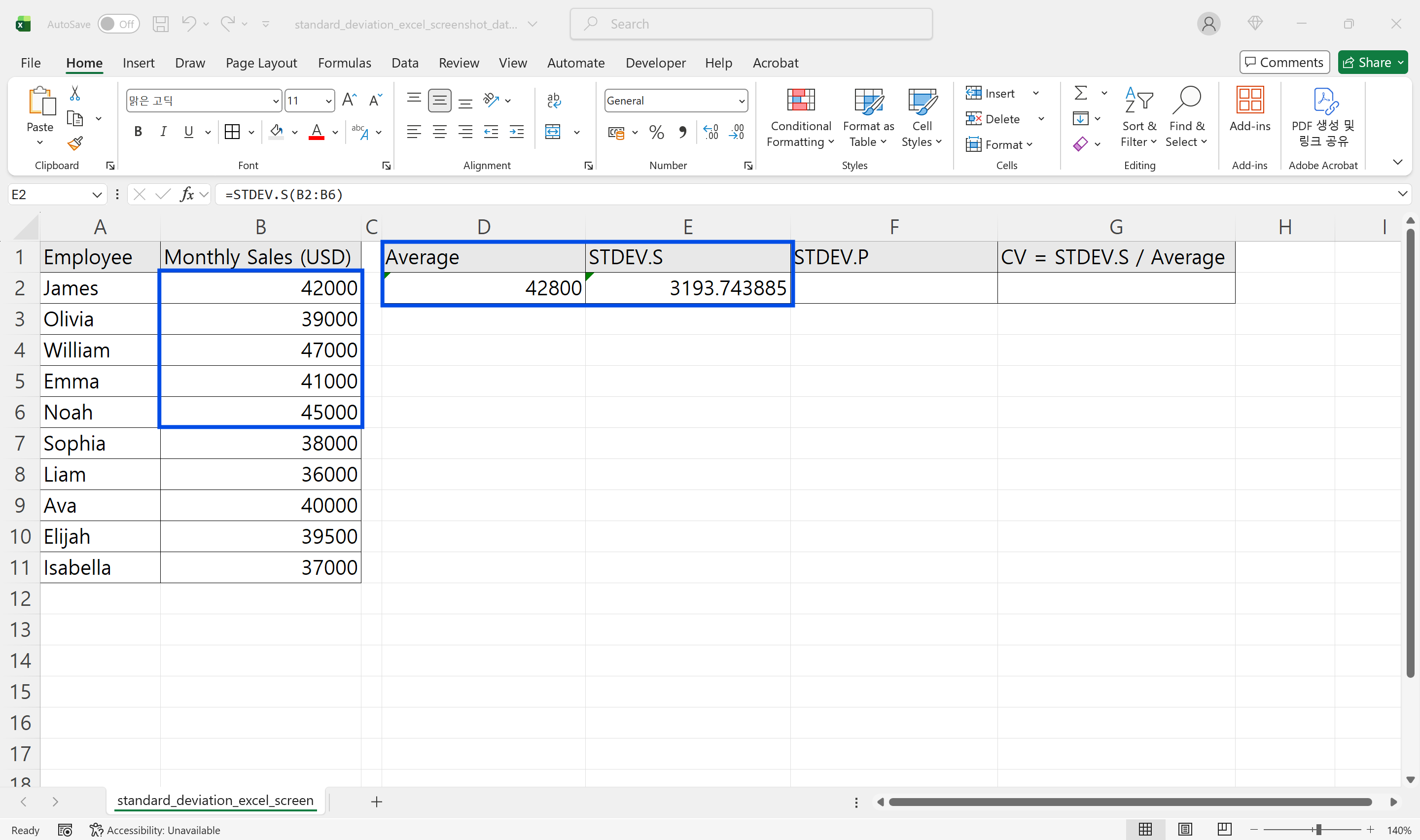
아래는 엑셀 표준편차 계산을 처음부터 끝까지 진행하는 실무 절차입니다. 판매팀 직원 5명의 월간 실적 데이터를 예시로 생각하면 됩니다.
- 데이터가 모집단인지 표본인지 먼저 정의합니다. 팀 전체 실적이라면
STDEV.P, 전체 중 일부라면STDEV.S를 선택합니다. - 표준편차를 출력할 셀을 클릭합니다.
=STDEV.S(또는=STDEV.P(를 입력합니다.- 분석할 데이터 범위를 드래그해 선택하고 괄호를 닫습니다. 예를 들어
=STDEV.S(B2:B6)처럼 입력합니다. - Enter를 누르면 엑셀 표준편차 계산 결과가 출력됩니다.
같은 범위에 =AVERAGE(B2:B6)도 함께 계산해 나란히 두면 해석이 훨씬 쉬워집니다.
STDEV.S와 STDEV.P는 모두 텍스트와 빈 셀을 무시하고 숫자만 계산합니다. 다만 STDEV.S는 숫자 데이터가 2개 미만이면 #DIV/0! 오류를 반환하고, STDEV.P는 숫자 데이터가 1개면 0을 반환하며 숫자 데이터가 하나도 없을 때 오류가 납니다.
엑셀 표준편차 숫자는 나왔는데 해석이 틀리는 이유
엑셀 표준편차는 계산보다 해석에서 실수가 더 많이 납니다. 자주 나오는 오해 패턴을 짚어드립니다.
표준편차가 크면 무조건 나쁘다는 오해
표준편차는 변동성이 큰 상태를 뜻하지만, 신규 캠페인 초기 구간이나 이벤트 기간처럼 원래 변동성이 클 수밖에 없는 상황도 있습니다. 숫자 자체보다 왜 흔들리는가를 먼저 따지는 게 맞습니다.
단위가 다른 지표를 직접 비교하는 실수
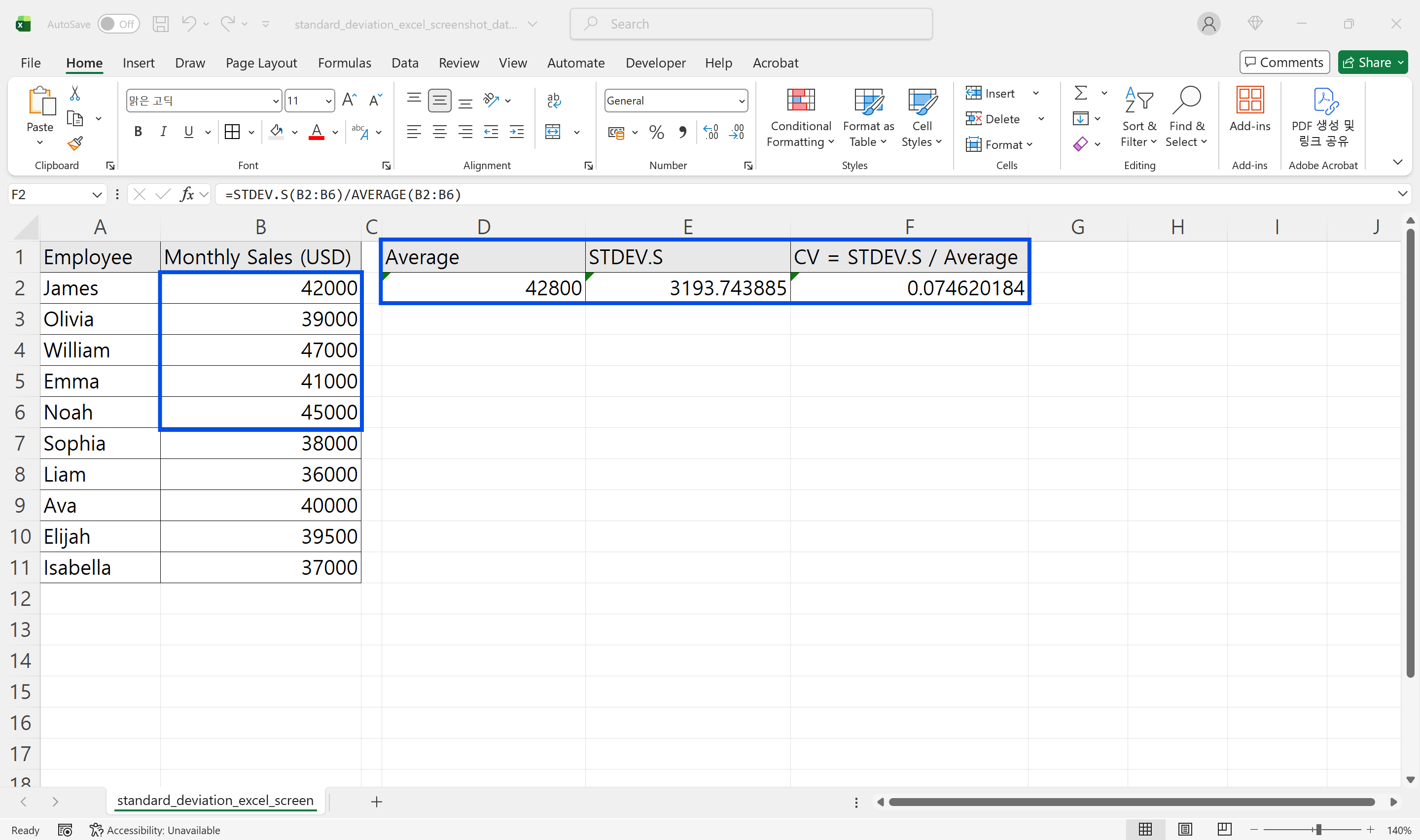
표준편차는 원래 단위를 그대로 가집니다. 매출과 처리 시간의 표준편차를 그대로 비교하면 결론이 왜곡됩니다. 이럴 때는 평균 대비 표준편차의 비율인 변동계수(CV)를 함께 보는 것이 합리적입니다.
엑셀에서는 다음처럼 간단히 구할 수 있습니다.
=STDEV.S(B2:B11)/AVERAGE(B2:B11)
이 값이 10% 미만이면 균일한 편, 30%를 넘으면 변동성이 크다고 판단할 수 있습니다. 다만 업종과 지표 특성에 따라 기준은 조정해야 합니다.
STDEV.P와 STDEV.S를 바꿔 써도 비슷할 거라는 착각
데이터가 10개 미만인 경우에는 함수 선택에 따라 결론이 달라질 수 있습니다. 팀 내 리포트 기준으로 어느 STDEV 함수를 쓸지 통일해두는 것이 좋습니다.
실무 데이터 분석에서 엑셀 표준편차 활용 기준
엑셀 표준편차를 실무에 제대로 활용하려면 몇 가지 기준을 잡아두는 것이 중요합니다.
동일 지표는 동일 함수로 고정합니다
주간 성과는 항상 STDEV.S 사용처럼 팀 내 룰을 정해두면 회의 때 함수 논쟁이 줄고 지표 해석 품질이 올라갑니다. 표본/모집단 전제가 섞인 리포트는 비교 자체가 무의미해질 수 있습니다.
표준편차는 평균과 세트로 KPI화합니다
표준편차만 단독으로 제시하면 크고 작음을 판단할 근거가 없습니다. 평균은 목표를 초과하는데 표준편차도 큰 상태라면 불안정한 성장으로, 평균은 낮지만 표준편차도 작은 상태라면 안정적이지만 개선이 필요한 상황으로 읽을 수 있습니다. 평균과 엑셀 표준편차 계산 결과를 한 덩어리로 두고 보는 습관이 분석 수준을 높입니다.
표본이 작을수록 결론을 보수적으로 냅니다
데이터 수가 적을수록 이상치 하나가 표준편차 전체를 흔들 수 있습니다. 이럴 때는 결론이 아니라 신호로 취급하고 추가 데이터를 확보한 뒤 재검토하는 편이 안전합니다.
엑셀 표준편차 구하는 법 FAQ
STDEV와 STDEV.S는 결과가 같은가요?
네, 동일합니다. STDEV는 Excel 2010 이전 버전의 함수 이름이고, STDEV.S는 이후 버전에서 목적을 더 명확히 하기 위해 이름을 바꾼 것입니다. 현재는 STDEV.S 사용을 권장합니다.
엑셀 표준편차 구하는 법에서 빈 셀이 포함되면 오류가 나나요?
아닙니다. STDEV.S와 STDEV.P 모두 빈 셀과 텍스트를 자동으로 무시하고 숫자만 계산합니다. 다만 숫자처럼 보이는 텍스트 형식 셀은 계산에서 제외되므로, 원데이터 형식을 미리 확인해두는 것이 좋습니다.
표준편차가 0으로 나왔어요. 오류인가요?
오류가 아닙니다. 범위 내 모든 값이 동일하면 표준편차는 0이 됩니다. 데이터 변동이 전혀 없다는 의미입니다.
데이터가 몇 개 이하면 엑셀 표준편차 계산 해석을 조심해야 하나요?
일반적으로 데이터가 10개 미만이면 이상치 하나가 전체 표준편차를 크게 바꿀 수 있습니다. 이 경우 결론보다는 참고 지표로 활용하고, 추가 데이터를 확보한 뒤 재검토하는 것이 안전합니다.
음수 데이터가 포함되면 계산에 문제가 생기나요?
아닙니다. 표준편차는 각 값과 평균의 차이를 제곱해 계산하기 때문에 음수 데이터가 포함되어도 정상적으로 작동합니다.
통계 분석, 이제 말로 시키세요
표준편차 계산 자체는 어렵지 않습니다. 반복이 문제입니다. 여러 시트의 데이터를 범위 지정하고, 팀마다 같은 함수를 복사해 적용하고, 보고서 형식에 맞게 다시 정리하는 과정이 매번 돌아옵니다.
inline AI는 지금 열려 있는 엑셀 파일을 직접 읽고 편집하는 Desktop-native AI입니다. "각 팀별 판매 실적 표준편차랑 평균 같이 구해줘"라고 말하면 됩니다. 함수 선택부터 범위 지정, 결과 정리까지 실시간으로 처리됩니다. STDEV.P와 STDEV.S 중 어떤 걸 써야 할지 모르겠으면 그냥 물어보면 됩니다.
데이터는 PC 밖으로 나가지 않습니다. 원가, 실적, 고객 데이터 모두 로컬에서 안전하게 처리됩니다.
매번 반복되는 통계 작업, 이제 inline AI에게 맡겨보세요.
내 컴퓨터 안의 AI 비서, inline AI 다운로드하기




