블로그
PDF 엑셀 변환 시 표가 깨지는 이유는? 원인 분석부터 무료 해결 방법까지
 Sik Yang · 2026년 2월 5일
Sik Yang · 2026년 2월 5일PDF 재무제표를 받았습니다. 숫자를 엑셀로 옮겨서 분석해야 합니다. 붙여넣으니 열이 전부 어긋나고, 숫자는 문자로 바뀌고, 셀은 엉뚱하게 병합됩니다. 변환 작업에 30분, 후처리에 1시간. 이 비효율의 근본 원인은 PDF의 구조 자체에 있습니다.
이 글에서는 PDF 변환이 실패하는 진짜 이유를 구조적으로 설명하고, 문서 유형별로 가장 빠른 해결 방법을 정리합니다. 아는 사람은 30분 안에 끝냅니다.

PDF가 엑셀에서 깨지는 진짜 이유: 애초에 '표'가 없습니다
PDF 변환이 어려운 이유는 도구 성능만의 문제가 아니라 PDF 포맷 자체의 구조적 특성에 있습니다.
시각적 좌표 중심 구조와 논리적 그리드의 차이
PDF는 데이터를 행과 열로 저장하지 않습니다. 대신 특정 좌표에 특정 글자를 그리는 방식으로 문서를 구성합니다.
예를 들어 사람 눈에는 2행 3열의 10,000처럼 보이더라도 PDF 내부에서는 좌표값에 따라 문자들이 배치된 상태에 가깝습니다. 반면 엑셀은 행과 열이 명확한 논리적 그리드 구조입니다.
그래서 PDF를 엑셀로 변환하는 과정은 흩어진 좌표값을 보고 같은 행과 열을 추정하는 작업이 됩니다. 이 추정이 어긋나는 순간 표 깨짐 현상이 발생합니다.
인코딩 문제와 보이지 않는 제어 문자
PDF를 만든 프로그램에 따라 눈에 보이지 않는 공백, 탭, 줄바꿈 문자가 끼어 있는 경우도 많습니다. 이런 문자가 엑셀로 들어오면 아래 같은 문제가 생깁니다.
- 숫자가 문자로 인식됨
- 셀 내부 줄바꿈이 비정상적으로 생김
#VALUE!같은 수식 오류가 발생함
이 문제는 회계, 재무, 정산 데이터에서 특히 자주 나타납니다.
변환 전 딱 이것 하나만 확인하세요: 텍스트 PDF인가, 이미지 PDF인가
변환 성공률을 높이려면 먼저 PDF 유형을 구분해야 합니다.
텍스트 기반 PDF
워드, 엑셀, ERP, 회계 프로그램 등에서 디지털로 직접 생성된 PDF입니다.
- 텍스트를 마우스로 선택할 수 있습니다.
Ctrl + F검색이 됩니다.- 엑셀 기능이나 전문 변환 도구로 구조를 비교적 잘 살릴 수 있습니다.
이미지·스캔 기반 PDF
종이 문서를 스캔했거나 화면 캡처를 PDF로 저장한 경우입니다.
- 텍스트 선택이 되지 않습니다.
- 검색이 되지 않습니다.
- OCR이 반드시 필요합니다.
이 구분을 잘못하면 아무리 좋은 도구를 써도 결과가 만족스럽지 않을 수 있습니다.
"왜 이렇게 됐지?" 변환 후 표 깨짐 3가지 패턴과 원인
1. 열 어긋남과 데이터 밀림
중간에 빈 셀이 있으면 변환 엔진이 이를 무시하고 다음 값을 앞으로 당겨 오면서 열 전체가 틀어질 수 있습니다.
2. 과도한 셀 병합
PDF의 시각적 배치를 그대로 흉내 내려고 하면서 엑셀에서 셀을 무리하게 병합하는 경우가 있습니다. 이 상태에서는 필터, 정렬, 피벗 테이블 사용이 어려워집니다.
3. 데이터 형식 혼선
쉼표, 통화 기호, 괄호 표기 때문에 숫자가 문자로 인식되면 이후 수식과 집계가 모두 깨질 수 있습니다.
PDF를 엑셀로 변환하는 현실적인 방법
문서 유형과 작업 빈도에 따라 접근 방법이 달라집니다.
초급: 마이크로소프트 워드를 브릿지로 활용
별도 설치 없이 빠르게 써 볼 수 있는 방법입니다. 워드의 PDF 리플로우 기능이 표 구조를 비교적 안정적으로 복원하는 편입니다.
- 워드에서 PDF 파일을 엽니다.
- 편집 가능한 문서로 변환하겠다는 안내를 확인합니다.
- 자동 생성된 표를 검토한 뒤 엑셀로 복사합니다.
이 방법은 가볍고 빠르지만, 표 구조가 복잡할수록 후처리가 필요할 수 있습니다.
중급: 구글 문서를 활용한 무료 OCR

스캔 PDF나 이미지 기반 PDF를 무료로 처리할 때 가장 현실적인 방법입니다.
- PDF를 구글 드라이브에 업로드합니다.
- 파일을 우클릭한 뒤
연결 앱 > Google 문서로 엽니다. - OCR 결과를 확인한 뒤 엑셀로 복사해 정리합니다.
이 방식은 한글 인식률이 비교적 좋고 복잡한 글꼴도 어느 정도 대응할 수 있지만, 완벽한 표 복원보다는 후처리의 출발점으로 보는 편이 좋습니다.
고급: 엑셀 Power Query 활용

정기적으로 PDF 데이터를 처리한다면 Power Query가 가장 강력합니다.
데이터 > 데이터 가져오기 > 파일에서 > PDF에서를 선택합니다.- PDF 파일을 불러오면 엑셀에서 내부 테이블 목록을 보여줍니다.
- 필요한 테이블만 선택하고
데이터 변환을 누릅니다. - 열 나누기, 데이터 형식 변경, 공백 제거 같은 정리를 진행합니다.
닫기 및 로드를 누르면 정리된 데이터가 엑셀 시트로 들어옵니다.
Power Query는 특정 테이블만 선택할 수 있고, 반복 작업 규칙을 재사용하기 좋다는 장점이 있습니다.
최종 검수 체크리스트
변환이 끝난 뒤에는 반드시 아래 항목을 확인해야 합니다.
- 숫자가 텍스트로 저장되지 않았는지 확인
TRIM,CLEAN함수로 보이지 않는 공백 제거- 병합 셀 해제 후 빈 셀 채우기
- 원본 PDF 합계와 엑셀 합계를 비교
이 마지막 검수 단계가 데이터 신뢰도를 좌우합니다.
어떤 도구를 쓰든 결국 후처리가 승부를 결정합니다
PDF를 엑셀로 변환하는 일은 단순한 파일 형식 변경이 아니라, 고정된 시각 정보를 분석 가능한 데이터로 복원하는 과정입니다.
그래서 하나의 만능 도구를 찾기보다 문서 유형에 따라 워드, 구글 OCR, Power Query를 조합해 쓰는 접근이 더 현실적입니다. 데이터 양이 많고 정확도가 특히 중요하다면 전문 OCR이나 유료 솔루션이 오히려 더 경제적일 수도 있습니다.
PDF 변환은 시작입니다. 후처리 1시간을 없애세요
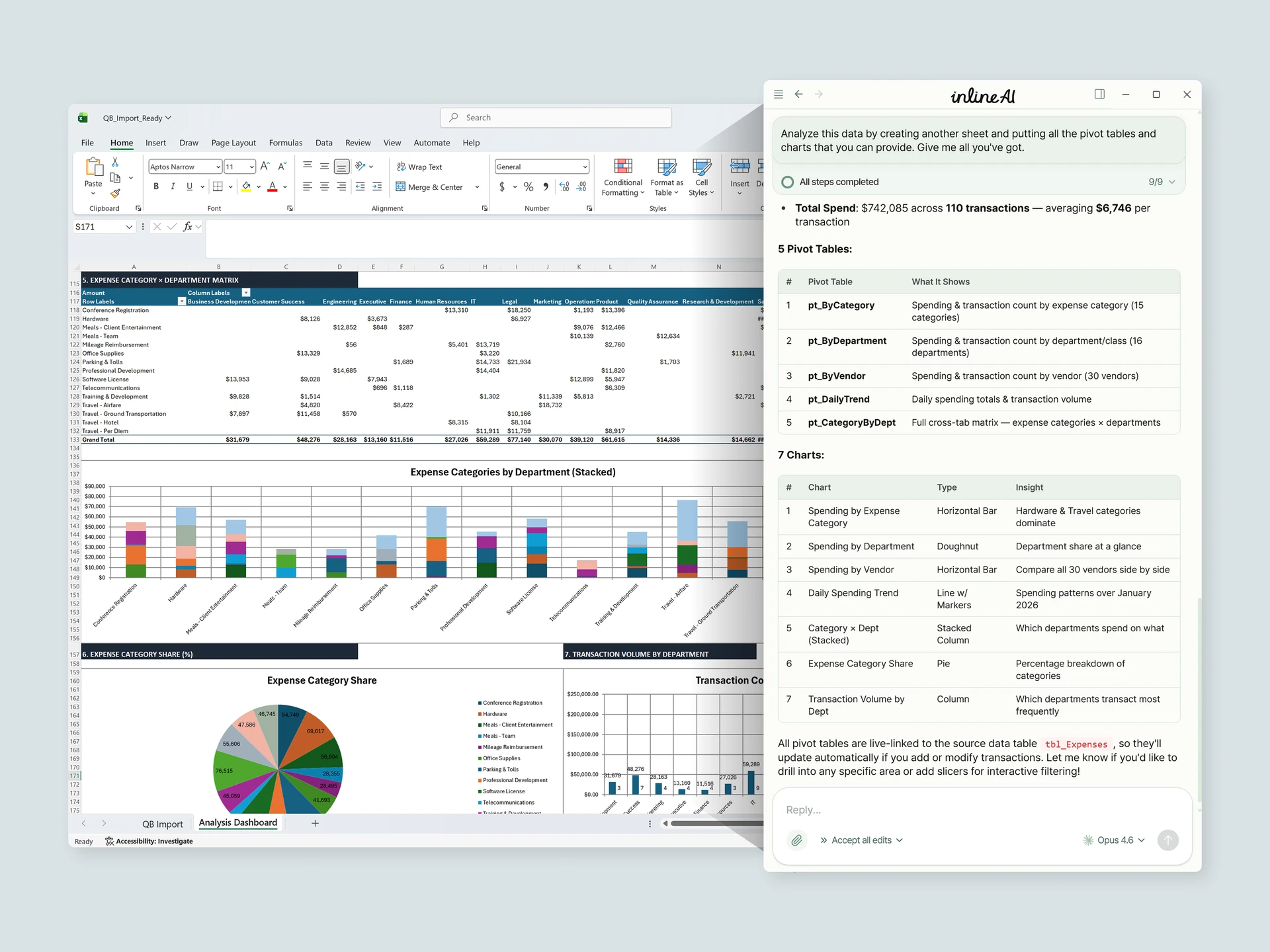
PDF 변환에 30분, 후처리에 1시간. 이건 도구 문제가 아니라 방식 문제입니다. 열 교정, 숫자 형식 변경, 공백 제거, 합계 검증을 전부 손으로 하면 당연히 오래 걸립니다.
inline AI는 이 후처리를 통째로 맡아 처리하는 데스크톱 기반 AI 동료입니다. "숫자 열 형식 다 바꿔줘", "공백 제거하고 원본 합계랑 비교해줘" 한 줄이면 됩니다. 재무제표도, 고객 데이터도, 전부 내 PC 안에서만 처리됩니다. 업로드도, 브라우저도 필요 없습니다.
내 컴퓨터 안의 AI 비서, inline AI 다운로드하기



